这个团队搞了个新的基准测试,用来测试视频语言模型的时间推理能力,在让他跟人类做对比,将文本、形状、视频的动态模式完全编码在时间域中,每一帧都像是电视没信号时的雪花屏,如果动起来,只要视力正常的人都能看出个大概,但是模型直接懵了
团队结果是:
人类参与者准确率98%
模型准确率0%
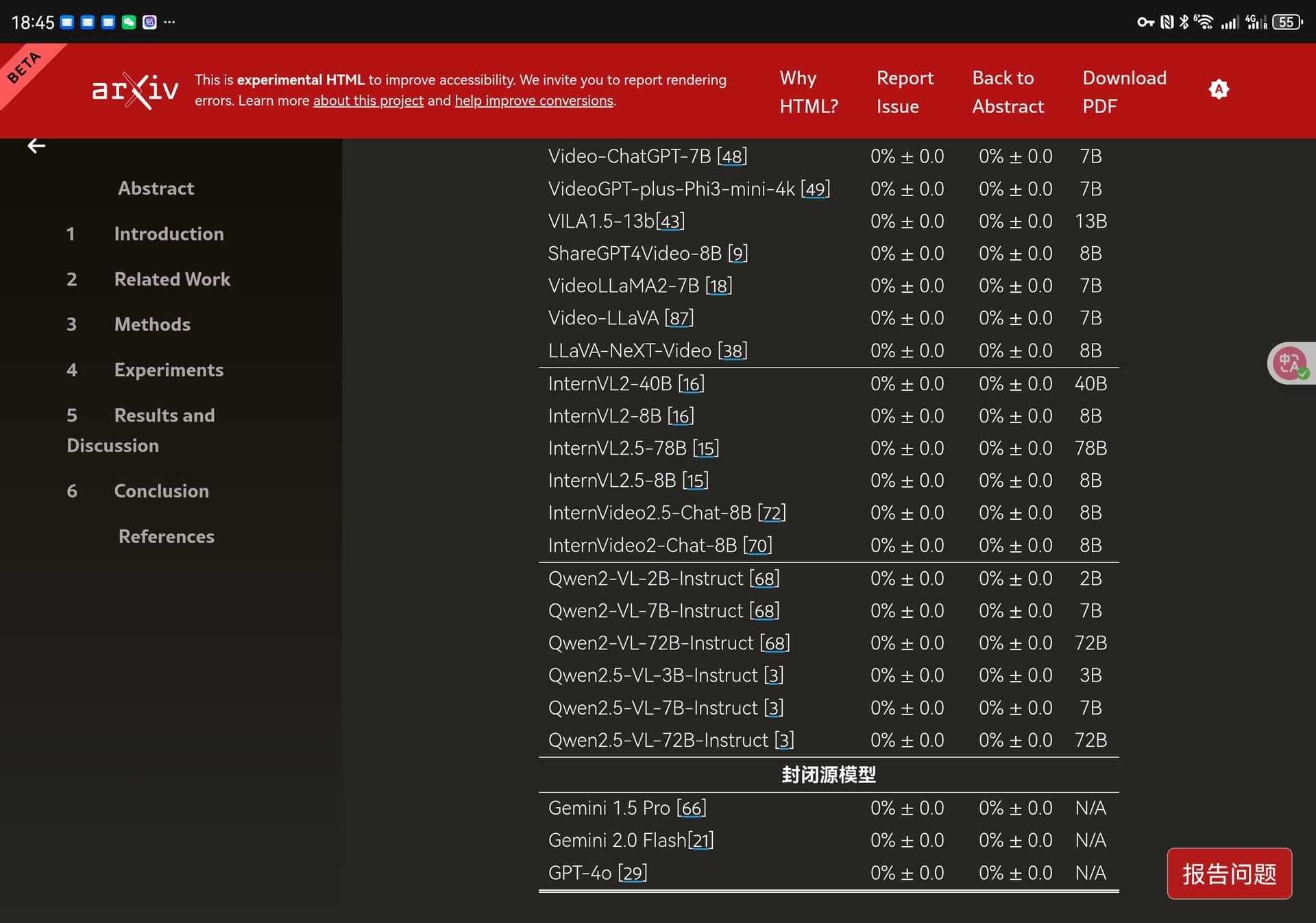
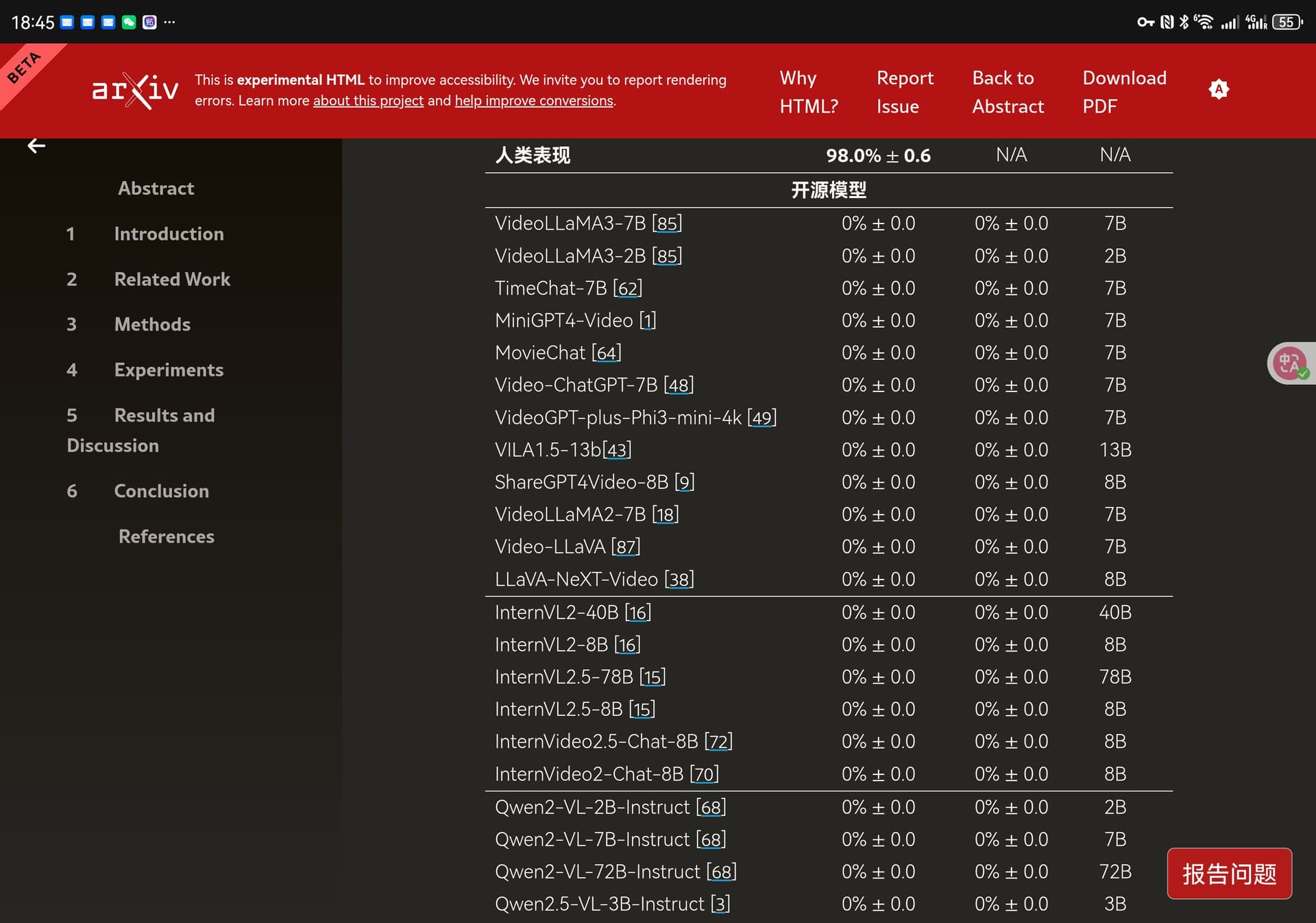
哪怕给模型提示词给直接提示、思维链、提高帧率也是一样识别不出来
团队经过测试的到了一个结果:
现在的模型只擅长处理静态图
缺乏从时间线索中提取意义的能力
说白了就是给你一个图片一个图片一起看,你也看不太出来
(他们先看这一帧是什么在一帧一帧的拼起来无法同时理解空间跟时间)